在科技日新月异的今天,人工智能(AI)技术正以前所未有的速度改变着我们的生活。作为AI领域的佼佼者,字节跳动旗下的豆包大模型团队再次传来振奋人心的消息——他们提出了全新的UltraMem架构,这一创新成果旨在解决MoE(Mixture of Experts,混合专家模型)推理时高额的访存问题,为AI应用端的发展开启了全新的“经济适用时代”。

UltraMem架构的问世,无疑是AI领域的一次重大突破。在过去,MoE模型以其高效的计算和参数解耦能力,在AI领域大放异彩。然而,随着模型规模的扩大,推理时的访存问题逐渐成为制约其广泛应用的关键因素。高昂的推理成本不仅增加了企业的运营成本,也限制了AI技术在更多场景下的应用。而UltraMem架构的出现,正是为了解决这一难题,让AI技术更加亲民、更加高效。
据豆包大模型团队介绍,UltraMem架构在保证模型效果的前提下,实现了推理成本的大幅降低。与传统的MoE架构相比,UltraMem在推理速度上实现了2-6倍的提升,推理成本最高可降低83%。这一数据不仅令人惊叹,更彰显了UltraMem架构在解决访存问题上的卓越能力。
那么,UltraMem架构究竟是如何实现这一突破的呢?这背后离不开团队在模型结构、值检索和参数扩展方面的多项创新。
在模型结构上,UltraMem借鉴了PKM(Product Key Memory)的设计,但并未止步于此。团队对PKM进行了改进和优化,将memory layer拆分为多个小层,并增加了skip-layer操作。这一设计使得模型可以并行地执行memory layer的访存操作和Transformer layer的计算,从而大大提高了推理效率。
在值检索方式上,UltraMem采用了更复杂的乘法方法——Tucker Decomposed Query-Key Retrieval(TDQKR)。这一方法受启发于Tucker Decomposition,通过组合乘加行score和列score,提高了value检索的复杂度,从而优化了模型效果。这不仅提升了检索的准确性,还进一步增强了模型的性能。
此外,在隐式扩展稀疏参数方面,UltraMem提出了Implicit Value Expansion(IVE)方法。该方法通过引入virtual memory和physical memory的概念,隐式地扩展了稀疏参数的数量,从而提高了模型的性能。同时,由于IVE方法中没有非线性操作,因此可以与physical memory table进行融合,生成全新的memory table,进一步降低了显存和部署成本。
为了验证UltraMem架构的有效性,豆包大模型团队在多个尺寸的激活参数上进行了广泛实验。实验结果表明,UltraMem在680M和1.6B的激活参数上具有显著的效果优势。随着稀疏参数的增加,UltraMem的效果和推理速度均表现出良好的扩展性。这一数据不仅证明了UltraMem架构的卓越性能,更为其在更多场景下的应用提供了有力支持。
让我们通过一个具体案例来深入了解UltraMem架构的实际应用效果。假设有一家电商企业希望利用AI技术提升用户购物体验。在过去,由于推理成本高昂,他们只能在小范围内应用AI技术。然而,在采用UltraMem架构后,他们得以大幅降低推理成本,从而实现了AI技术在全平台的广泛应用。这不仅提高了用户购物的便捷性和满意度,还为企业带来了更多的商业机会和收益。这一案例充分展示了UltraMem架构在解决实际问题中的巨大潜力。
UltraMem架构的成功推出,无疑为AI应用端的发展注入了新的活力。它不仅解决了MoE推理时高额的访存问题,还实现了推理成本和速度的双重突破。随着UltraMem架构的广泛应用,我们可以预见,AI技术将更加亲民、更加高效,为更多企业和用户带来实实在在的利益。
展望未来,随着AI技术的不断进步和创新,我们有理由相信,UltraMem架构将成为推动AI应用端进入“经济适用时代”的重要力量。它将助力更多企业和开发者在AI领域取得突破,为构建更加智能、便捷的未来世界贡献力量。让我们共同期待UltraMem架构在未来带来的更多惊喜和变革吧!
扫描下方二维码,一个老毕登免费为你解答更多软件开发疑问!

物业管理工单AI调度方案:维修响应缩短至30分钟的核心算法
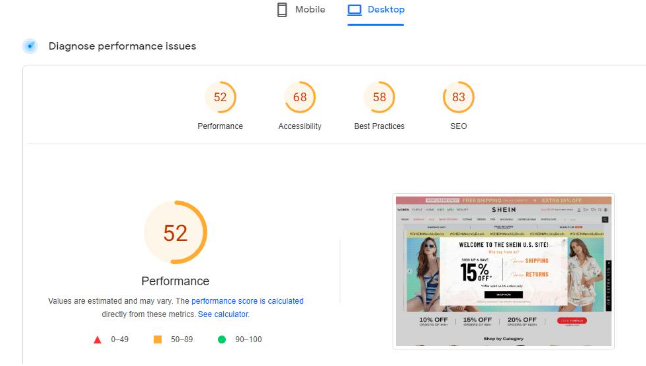
电商网站加速方案:WooCommerce加载从5s到0.9s的实操
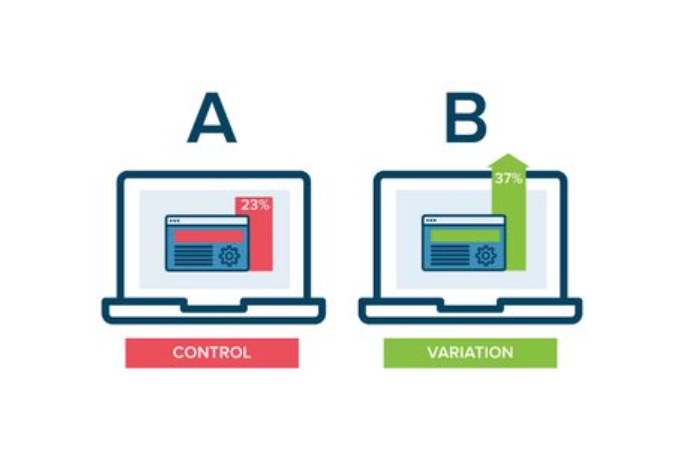
APP开发后如何做A/B测试? (转化率提升指南!界面/文案/按钮优化案例)