将PDF转换为HTML是一个相对复杂的过程,涉及到PDF文件的解析、内容的提取以及HTML格式的构建等多个步骤。下面将详细介绍如何将PDF转换为HTML,并尽量将字数扩展到1500字以上。
一、PDF与HTML的格式差异
首先,我们需要了解PDF和HTML这两种格式的基本差异。PDF(Portable Document Format)是一种电子文件格式,用于呈现文档,包括文本、图像、表格等多种元素,且能够保持在不同设备和操作系统上的一致性。而HTML(HyperText Markup Language)则是一种用于创建网页的标准标记语言,主要用于描述网页的结构和内容。
由于PDF和HTML在格式和结构上的差异,使得PDF转HTML的过程并非简单的格式转换,而是需要对PDF文件进行深入解析,提取出其中的内容,并按照HTML的规范进行重构。
二、PDF转HTML的方法
- 使用专业的PDF转换工具
目前市面上有许多专业的PDF转换工具,如SmallPDFer、Adobe Acrobat等,它们都提供了PDF转HTML的功能。这些工具通常具有强大的PDF解析能力,能够准确地提取出PDF文件中的内容,并生成高质量的HTML文件。
使用这些工具的一般步骤如下:
(1)打开PDF转换工具,选择“PDF转HTML”功能。
(2)将需要转换的PDF文件导入到工具中。
(3)根据需要,设置转换选项,如页面范围、输出格式等。
(4)点击开始转换按钮,等待转换完成。
(5)转换完成后,保存生成的HTML文件。
需要注意的是,虽然这些工具能够大大简化PDF转HTML的过程,但并非所有的PDF文件都能完美转换为HTML。特别是对于一些包含复杂布局、特殊字体或图像的PDF文件,转换后的HTML文件可能无法完全保留原始的视觉效果。
- 使用编程方式转换
除了使用专业的PDF转换工具外,还可以通过编程的方式实现PDF转HTML。这需要借助一些支持PDF解析和HTML生成的编程语言或库,如Python的pdfplumber和BeautifulSoup库等。
使用编程方式转换的一般步骤如下:
(1)选择合适的编程语言和库,安装并导入相关模块。
(2)编写代码,打开并解析PDF文件,提取出其中的内容。
(3)根据提取的内容,构建HTML文档的结构和样式。
(4)将生成的HTML文档保存到本地或输出到网页中。
通过编程方式转换PDF到HTML可以实现更高的灵活性和定制化需求。然而,这需要一定的编程基础和经验,对于非专业人士来说可能存在一定的学习成本。
三、转换过程中的注意事项
在进行PDF转HTML的过程中,需要注意以下几点:
- 转换前的备份:由于转换过程中可能会出现不可预测的问题,导致原始PDF文件损坏或丢失,因此在转换前务必对原始PDF文件进行备份。
- 转换质量的控制:转换质量是衡量转换效果的重要指标。在转换过程中,需要关注转换后的HTML文件是否能够准确呈现原始PDF文件的内容、布局和样式。为了提高转换质量,可以尝试调整转换工具的参数设置或使用更高级的PDF解析库。
- 转换效率的提升:对于大量PDF文件的转换需求,需要关注转换效率。可以通过优化转换流程、使用多线程或分布式处理等方式提高转换效率。
- 版权问题的处理:在转换过程中,需要遵守相关的版权法律法规,确保转换的HTML文件不侵犯他人的版权。如果需要分享或发布转换后的HTML文件,请务必获得原始PDF文件作者的授权或遵守相关的使用协议。
四、总结与展望
将PDF转换为HTML是一个具有挑战性和实用性的任务。通过选择合适的转换方法、注意转换过程中的细节问题以及不断优化转换效果,我们可以实现高质量的PDF到HTML的转换。未来,随着技术的不断发展和完善,相信会有更多高效、智能的PDF转HTML工具和方法出现,为我们的生活和工作带来更多便利。
在总结上述内容的同时,我们也应该认识到PDF转HTML任务的复杂性和多样性。不同的PDF文件可能具有不同的结构、内容和需求,因此在实际应用中需要根据具体情况选择合适的转换方法和工具。同时,我们也应该关注转换后的HTML文件在网页中的呈现效果和用户体验,确保转换结果能够满足实际需求并带来良好的用户体验。
最后,希望本文能够为大家提供关于如何将PDF转换为HTML的详细指导和建议,并在实际应用中发挥一定的参考价值。
扫描下方二维码,一个老毕登免费为你解答更多软件开发疑问!

物业管理工单AI调度方案:维修响应缩短至30分钟的核心算法
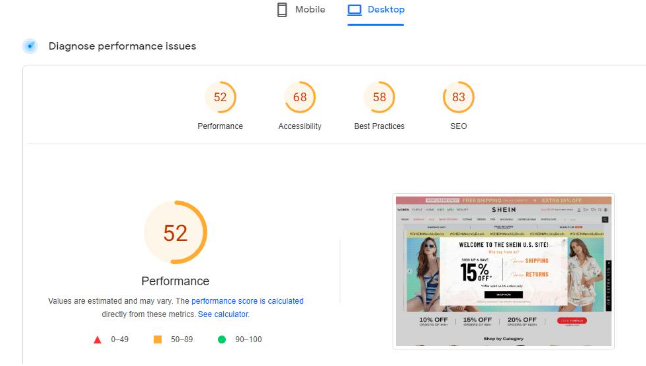
电商网站加速方案:WooCommerce加载从5s到0.9s的实操
APP开发后如何做A/B测试? (转化率提升指南!界面/文案/按钮优化案例)