Coredump,作为软件开发中的一个重要概念,尤其在Linux系统环境下,是开发者们进行程序调试和问题定位时不可或缺的工具。下面将从定义、产生条件、存储与命名、分析方法以及应用场景等多个方面,对Coredump进行详细解析。

一、定义
Coredump,即核心转储,是指在程序运行过程中,当检测到异常或错误(如内存访问越界、空指针引用、堆栈溢出等)导致程序异常退出或崩溃时,操作系统将程序当前的内存状态、寄存器状态、堆栈指针、内存管理信息以及函数调用堆栈信息等保存到一个文件中。这个文件通常被称为Core文件,它记录了程序崩溃时的“现场”,为开发者提供了宝贵的调试信息。
二、产生条件
Coredump的产生需要满足一定的条件,主要包括:
- 程序异常退出:程序因检测到无法处理的错误(如内存访问越界、空指针引用等)而异常退出。
- 系统配置:Linux系统需要配置允许生成Coredump,这通常通过
ulimit -c命令来设置。如果设置为0,则不生成Coredump文件。 - 文件权限:当前用户需要具有写入Coredump文件的权限,以及足够的磁盘空间来存储该文件。
- 进程状态:某些特定的进程状态(如设置了SUID或SGID且当前用户不是程序文件的所有者或所属组的成员)可能阻止Coredump的生成。
三、存储与命名
Coredump文件的存储位置和命名规则可以通过系统配置进行调整。默认情况下,Coredump文件保存在与程序相同的目录下,文件名通常为“core”。然而,为了避免文件名冲突和便于管理,可以通过修改/proc/sys/kernel/core_pattern文件来指定Coredump文件的存储位置和命名规则。例如,可以将其设置为“/data/coredump/core.%e.%p”,这样生成的Coredump文件名将包含崩溃的程序名和进程ID,如“core.myprogram.12345”。
四、分析方法
Coredump文件的分析通常依赖于调试工具,如GDB(GNU Debugger)。开发者可以使用GDB加载Coredump文件和对应的可执行程序,通过查看程序崩溃时的内存状态、寄存器值、堆栈指针以及函数调用堆栈等信息,来定位问题的根源。此外,还可以使用readelf等工具查看Coredump文件的ELF头部信息,以确认其格式和类型。
五、应用场景
Coredump在软件开发和运维中具有广泛的应用场景,包括但不限于:
- 程序调试:当程序崩溃时,生成Coredump文件可以帮助开发者快速定位问题所在,进行代码修复和优化。
- 稳定性分析:通过分析Coredump文件,可以了解程序的崩溃模式和频率,从而采取相应的措施提高程序的稳定性和可靠性。
- 安全审计:在某些情况下,Coredump文件还可以用于安全审计和漏洞挖掘,帮助开发者发现和修复潜在的安全风险。
六、注意事项
在使用Coredump时,需要注意以下几点:
- 隐私保护:Coredump文件中可能包含敏感信息(如用户数据、密码等),因此在处理Coredump文件时需要谨慎,确保不会泄露隐私信息。
- 磁盘空间:Coredump文件可能会占用大量的磁盘空间,因此需要根据实际情况合理设置Coredump文件的大小限制和存储策略。
- 性能影响:生成Coredump文件可能会对系统性能产生一定的影响,特别是在程序频繁崩溃的情况下。因此,需要在性能和调试需求之间找到平衡点。
扫描下方二维码,一个老毕登免费为你解答更多软件开发疑问!

物业管理工单AI调度方案:维修响应缩短至30分钟的核心算法
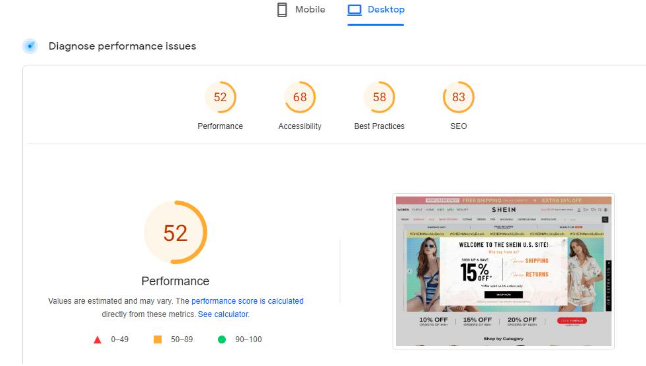
电商网站加速方案:WooCommerce加载从5s到0.9s的实操
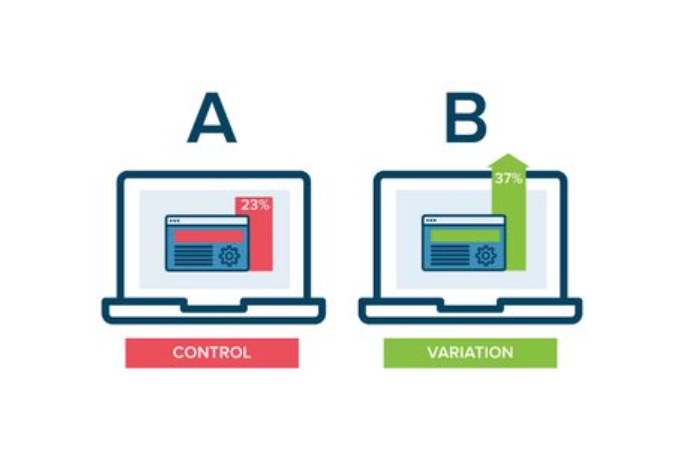
APP开发后如何做A/B测试? (转化率提升指南!界面/文案/按钮优化案例)