机器学习模型(Machine Learning Model)是软件开发中一个至关重要的概念,它代表了通过机器学习算法从数据中自动学习并构建起来的数学模型。这些模型能够接收输入数据,并根据学到的规律或模式进行预测、分类、聚类或其他任务。为了详细解释这一术语,以下将从定义、工作原理、类型、构建过程以及一个实例形象的讲解等几个方面进行阐述。

一、定义
机器学习模型是指一种能够从数据中自动学习并构建起来的数学模型。它利用机器学习算法,通过训练数据集来学习数据的内在规律和模式,从而能够对新的输入数据进行预测或决策。与传统的基于规则的编程方法不同,机器学习模型更注重从数据中提取特征,并通过迭代优化来不断提高其性能。
二、工作原理
机器学习模型的工作原理基于统计学、优化理论和计算机科学等多个领域的知识。在训练阶段,模型通过不断调整其内部参数(如权重、偏差等)来最小化预测输出与真实标签之间的误差。这通常通过梯度下降、随机梯度下降等优化算法来实现。在预测阶段,模型接收新的输入数据,并根据学到的规律和模式进行预测或决策。
三、类型
机器学习模型根据其学习方式和应用场景的不同,可以分为多种类型。常见的包括:
- 监督学习模型:在训练过程中,模型接收已标注的输入输出数据对,并学习输入到输出的映射关系。常见的监督学习模型有线性回归、逻辑回归、决策树、支持向量机等。
- 无监督学习模型:与监督学习不同,无监督学习模型在训练过程中不接收已标注的数据。它们的目标是发现数据中的潜在结构或模式,如聚类、降维等。常见的无监督学习模型有K-均值聚类、主成分分析等。
- 强化学习模型:强化学习模型通过与环境的交互来学习最佳策略。它们根据不同动作的结果(奖励或惩罚)来更新策略,以最大化累积奖励。常见的强化学习算法有Q-learning、Deep Q-Network(DQN)等。
四、构建过程
构建机器学习模型通常包括以下几个步骤:
- 数据收集:收集与任务相关的数据集,确保数据的质量和完整性。
- 数据预处理:对收集到的数据进行清洗、转换和规范化,以消除噪声、填补缺失值,并使其适合机器学习算法的处理。
- 特征选择:从原始数据中提取有用的特征,这些特征将作为机器学习模型的输入。特征选择的好坏直接影响到模型的性能。
- 模型选择:根据任务需求和数据特点选择合适的机器学习算法。
- 模型训练:使用训练数据集对模型进行训练,调整其内部参数以最小化预测误差。
- 模型评估:使用测试数据集对训练好的模型进行评估,衡量其性能。
- 模型部署:将训练好的模型部署到实际应用场景中,进行预测或决策。
五、实例讲解
以线性回归模型为例,假设我们要预测波士顿地区的房价。首先,我们收集了一个包含波士顿地区房价及相关特征(如房间数、卧室数、地理位置等)的数据集。然后,我们对数据进行预处理,包括清洗数据、填补缺失值、标准化特征等。接着,我们选择线性回归算法作为我们的模型,并使用训练数据集对模型进行训练。在训练过程中,模型不断调整其权重和偏差参数,以最小化预测房价与实际房价之间的误差。最后,我们使用测试数据集对训练好的模型进行评估,并发现模型在测试数据集上的表现良好。因此,我们可以将训练好的线性回归模型部署到实际应用场景中,用于预测波士顿地区的房价。
综上所述,机器学习模型是一种能够从数据中自动学习并构建起来的数学模型。它通过不断调整内部参数来最小化预测误差,并能够应用于各种实际场景中。在实际应用中,我们需要根据任务需求和数据特点选择合适的机器学习算法,并经过数据收集、预处理、特征选择、模型选择、训练、评估和部署等步骤来构建和部署机器学习模型。
扫描下方二维码,一个老毕登免费为你解答更多软件开发疑问!

物业管理工单AI调度方案:维修响应缩短至30分钟的核心算法
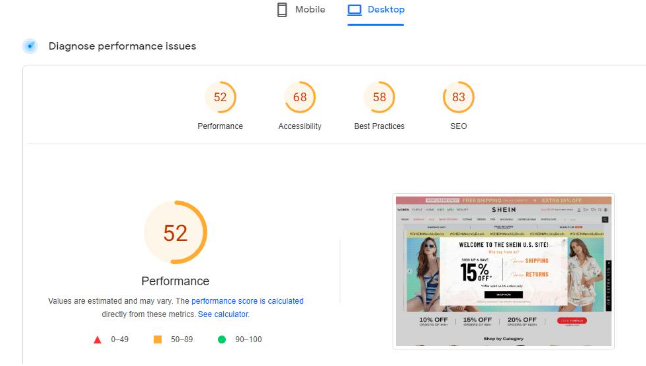
电商网站加速方案:WooCommerce加载从5s到0.9s的实操
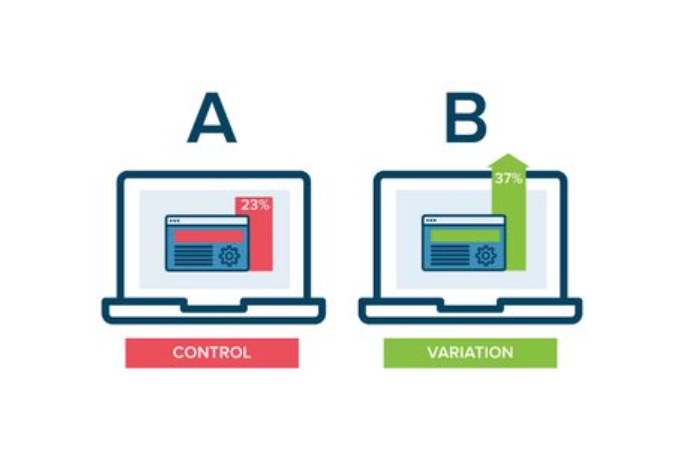
APP开发后如何做A/B测试? (转化率提升指南!界面/文案/按钮优化案例)