Cassandra是一个高度可扩展的分布式NoSQL数据库系统,最初由Facebook开发,用于存储收件箱等简单格式数据,后来被开源并受到广泛关注和应用。以下是对Cassandra的详细解释,包括其特点、工作原理、应用场景以及一个实例讲解。

一、Cassandra的特点
- 分布式架构:Cassandra采用分布式架构,可以运行在多台机器上,但作为一个统一的整体呈现给用户。这种架构使得Cassandra能够处理大规模的数据存储和查询需求,同时提供高可用性和容错性。
- 去中心化:Cassandra不存在单一故障点,集群中所有节点的功能都完全一样,因为它们都做同样的工作。这种去中心化的设计使得Cassandra在节点故障时能够自动恢复,保证系统的连续性和稳定性。
- 弹性可扩展性:Cassandra集群能够接受新节点的加入,且不需要重新配置整个集群。新节点加入后,Cassandra能够自动发现并开始使用它,实现弹性可扩展性。
- 高可用性:Cassandra通过复制机制将数据存储在多个节点上,当某个节点发生故障时,可以从其他节点获取数据副本,保证数据的高可用性。
- 容错性:Cassandra能够容忍节点故障,并在故障发生时自动进行恢复,保证系统的连续性和数据的完整性。
- 支持多数据中心复制:Cassandra支持将数据复制到多个数据中心,以提高数据的可用性和本地性能。
二、Cassandra的工作原理
Cassandra采用了宽列存储模型(Wide Column Store),其数据模型由以下几个核心概念组成:
- 键空间(Keyspace):类似于关系型数据库中的数据库,是Cassandra中存储数据的逻辑单元。
- 表(Table):类似于关系型数据库中的表,但Cassandra中的表是分布式的,可以跨多个节点存储数据。
- 行(Row):存储数据的基本单位,每行包含一个主键和多个列。
- 列族(Column Family):一组具有相同名称和类型的列的集合,类似于关系型数据库中的表结构,但更加灵活。
Cassandra通过一致性哈希算法将数据均匀分布在集群中的各个节点上,客户端通过协调节点(coordinator node)来进行数据读写操作。在数据读写过程中,Cassandra支持多种一致性级别,包括强一致性、最终一致性和会话一致性,用户可以根据应用的需求选择合适的一致性级别。
三、Cassandra的应用场景
Cassandra非常适合用于处理大规模数据的场景,如:
- 时间序列数据:如日志、传感器数据等,Cassandra能够处理海量的数据写入和高频率的数据查询。
- 事件日志数据:如用户行为日志、系统日志等,Cassandra能够高效地存储和查询这些日志数据。
- 用户活动记录:如用户点击、浏览、购买等行为记录,Cassandra能够实时地存储和更新这些数据。
- 消息数据:如即时通讯消息、邮件等,Cassandra能够支持高并发的消息存储和查询。
- 社交网络数据:如用户关系、帖子、评论等,Cassandra能够处理复杂的社交网络数据结构和查询需求。
四、实例讲解
以下是一个使用Cassandra存储和查询时间序列数据的实例讲解:
假设我们有一个物联网系统,需要实时地存储和查询传感器数据。每个传感器都有一个唯一的ID,并且会定期发送数据到系统中。我们可以使用Cassandra来存储这些传感器数据,并实时地查询和分析它们。
创建键空间和表:
- 创建一个键空间来存储传感器数据。
- 在键空间中创建一个表,用于存储传感器的ID、时间戳和数据值。
插入数据:
- 当传感器发送数据时,我们将数据插入到Cassandra表中。
- 使用传感器的ID作为主键,时间戳作为列名(或列族中的一部分),数据值作为列的值。
查询数据:
- 根据传感器的ID和时间范围来查询数据。
- Cassandra会返回指定时间范围内该传感器的所有数据值。
- 我们可以对这些数据进行进一步的分析和处理,如计算平均值、最大值、最小值等。
通过以上步骤,我们可以利用Cassandra来高效地存储和查询物联网系统中的传感器数据。Cassandra的分布式架构和高可用性特性使得它能够处理大规模的数据存储和查询需求,同时提供高性能和容错性。这使得Cassandra成为物联网系统、实时分析系统、互联网应用等大规模数据处理场景的理想选择。
扫描下方二维码,一个老毕登免费为你解答更多软件开发疑问!

物业管理工单AI调度方案:维修响应缩短至30分钟的核心算法
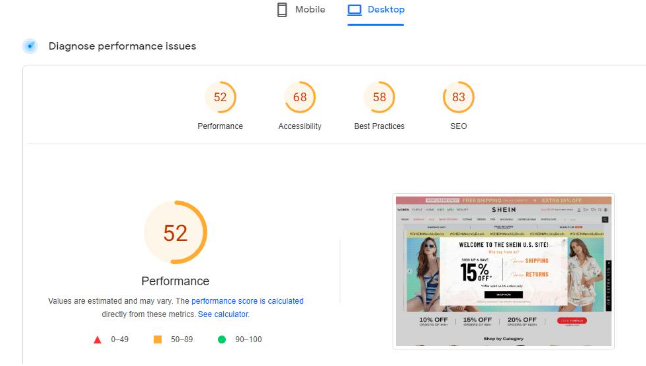
电商网站加速方案:WooCommerce加载从5s到0.9s的实操
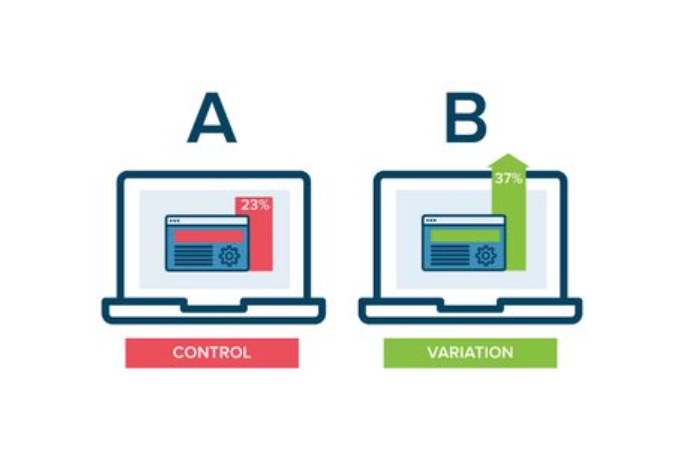
APP开发后如何做A/B测试? (转化率提升指南!界面/文案/按钮优化案例)