Replication(复制)是软件开发和数据库管理中的一个核心概念,特别是在分布式系统和数据高可用性领域。它指的是将数据从一个数据源(如数据库或文件系统)复制到另一个或多个数据源的过程,目的是提高数据的可用性、可靠性和性能。下面,我将详细解释Replication的概念,并通过一个实例来形象地说明其工作原理。

一、Replication的基本概念
Replication的核心思想是通过数据的冗余存储来提高系统的容错能力和性能。在分布式系统中,数据复制通常涉及多个节点或服务器,每个节点都存储着数据的副本。这些副本可以是完全相同的,也可以是根据特定规则同步的。
Replication的主要优势包括:
- 提高可用性:即使某个节点发生故障,其他节点上的数据副本仍然可用,从而保证了系统的持续运行。
- 负载均衡:通过将数据分布在多个节点上,可以减轻单个节点的负载,提高系统的整体性能。
- 数据恢复:在数据丢失或损坏的情况下,可以使用其他节点上的数据副本进行恢复。
二、Replication的工作原理
Replication的工作原理通常涉及以下几个关键步骤:
- 数据捕获:首先,需要捕获数据源上的数据变化。这可以通过读取数据库的日志、监听文件系统的事件或使用其他机制来实现。
- 数据传输:捕获到数据变化后,需要将这些变化传输到目标节点。这可以通过网络传输、文件复制或其他方式来完成。
- 数据应用:在目标节点上,接收到的数据变化需要被应用到本地的数据副本上,以保持与目标节点上数据的一致性。
三、Replication的实例讲解
为了更好地理解Replication的工作原理,我们可以通过一个简单的数据库复制实例来说明。
假设我们有两个数据库服务器,Server A和Server B,它们之间需要实现数据的双向复制。
配置复制环境:
- 在Server A和Server B上分别安装数据库软件,并配置好网络连接。
- 创建一个用于复制的用户账户,并授予相应的权限。
- 配置数据库日志和复制相关的参数,以确保数据捕获和传输的顺利进行。
启动复制进程:
- 在Server A上启动一个复制进程,该进程负责捕获数据库上的数据变化,并将这些变化传输到Server B。
- 同样地,在Server B上也启动一个复制进程,负责将Server B上的数据变化传输到Server A。
数据变化同步:
- 当Server A上的数据库发生数据变化时(如插入、更新或删除记录),复制进程会捕获这些变化,并将它们传输到Server B。
- Server B上的复制进程接收到这些变化后,会将其应用到本地的数据库副本上,从而保持与Server A上数据的一致性。
- 同样地,Server B上的数据变化也会通过复制进程同步到Server A上。
监控和管理:
- 为了确保复制过程的顺利进行,需要定期监控复制状态、检查错误日志,并及时处理任何潜在的问题。
- 可以使用数据库提供的复制管理工具或第三方监控工具来实现这一目的。
通过上述实例,我们可以看到Replication如何通过数据的冗余存储和同步来提高系统的可用性、可靠性和性能。在实际应用中,Replication技术还可以结合负载均衡、故障转移和数据恢复等机制来进一步提高系统的健壮性和灵活性。
总之,Replication是软件开发和数据库管理中的一个重要概念,它为实现数据的高可用性和可靠性提供了有力的支持。通过合理的配置和管理,Replication可以确保数据在分布式系统中的一致性和安全性。
扫描下方二维码,一个老毕登免费为你解答更多软件开发疑问!

物业管理工单AI调度方案:维修响应缩短至30分钟的核心算法
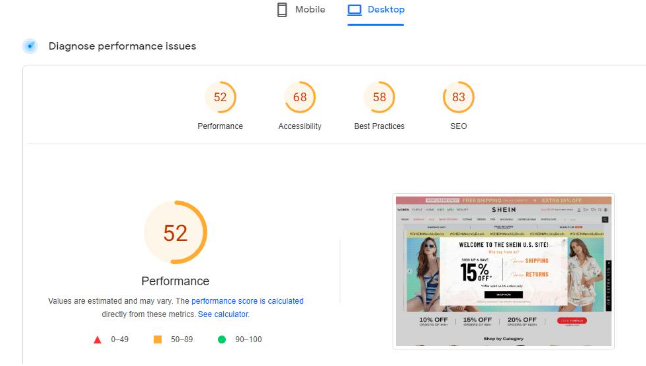
电商网站加速方案:WooCommerce加载从5s到0.9s的实操
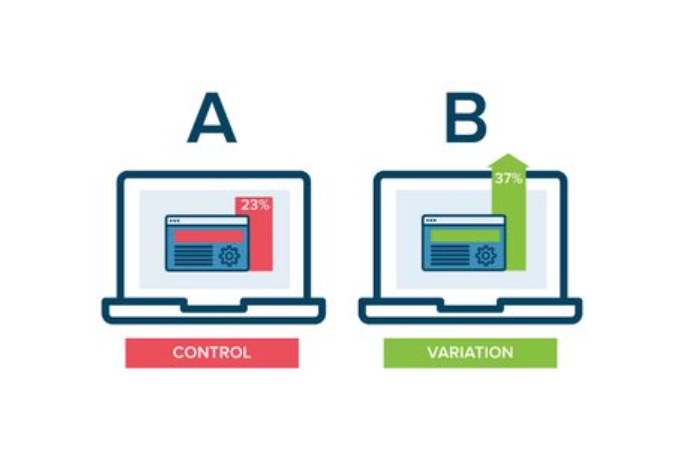
APP开发后如何做A/B测试? (转化率提升指南!界面/文案/按钮优化案例)