在软件开发中,yield(动词,意为“产生”)是一个具有特定含义和用途的关键字,尤其在Python、C#等编程语言中扮演着重要角色。以下是对yield的详细解释,包括其工作原理、使用场景以及一个实例形象的讲解。
一、yield的工作原理
yield关键字通常用于创建生成器(generator),这是一种特殊类型的迭代器,允许用户定义迭代行为而不需要实现类中的迭代器协议方法。当函数中包含yield语句时,调用这个函数并不会立即执行其全部代码,而是返回一个迭代器。每次从迭代器中获取一个值时(通常是通过循环或next()函数),函数会执行到下一个yield语句为止,并再次暂停,保持执行状态。这允许函数在保持低内存消耗的同时,按需生成值。
二、yield的使用场景
yield的使用提供了一种优雅的处理大数据集或无限序列的方法,同时又不必一次将所有数据加载到内存。这尤其适用于有限内存环境或对内存消耗敏感的应用。此外,在构建有状态的协程时,yield也扮演着至关重要的角色。它允许函数在保持中间状态的同时,暂停执行并在适当时机恢复,这对于管理复杂的控制流程特别有效。
具体来说,yield的使用场景包括但不限于:
- 数据流处理:通过生成器按需处理数据流,避免一次性加载整个数据集。
- 数据管道创建:利用生成器构建数据管道,实现数据的逐步处理和传输。
- 生成无限序列:使用生成器可以方便地生成无限序列,如斐波那契数列等。
- 实现协程:在异步编程中,yield可以用于实现协程,实现多个任务间的协作和切换。
三、实例讲解
以下是一个使用yield创建生成器的Python实例,用于形象地解释yield的工作原理:
pythondef count_up_to(max_value): count = 1 while count <= max_value: yield count count += 1 # 使用生成器 counter = count_up_to(5) for value in counter: print(value)
在这个例子中,count_up_to函数是一个生成器,它会逐步产生一系列数字,直到指定的max_value。当调用这个函数时,它不会立即执行完整个循环,而是返回一个迭代器。每次通过迭代器获取一个值时,函数会执行到下一个yield语句为止,并返回当前的count值,然后暂停执行。下一次调用迭代器时,函数会从上次暂停的地方继续执行,并返回下一个count值。
输出结果如下:
1 2 3 4 5
这个实例展示了yield如何允许函数在保持低内存消耗的同时,按需生成值。与传统的return语句不同,yield不会结束函数的执行,而是暂停函数并返回一个值,同时保留函数的执行状态和局部变量。这使得生成器能够处理大型数据集或无限序列,而不会导致内存溢出。

四、总结
yield是软件开发中一个强大的工具,它允许函数在保持中间状态的同时按需生成值。这种特性使得yield在处理大数据集、构建数据管道、生成无限序列以及实现协程等方面具有广泛的应用。通过理解yield的工作原理和使用场景,开发者可以更加高效地编写代码,优化性能和内存使用。同时,合理使用yield也能提升代码的可读性和可维护性。
扫描下方二维码,一个老毕登免费为你解答更多软件开发疑问!

物业管理工单AI调度方案:维修响应缩短至30分钟的核心算法
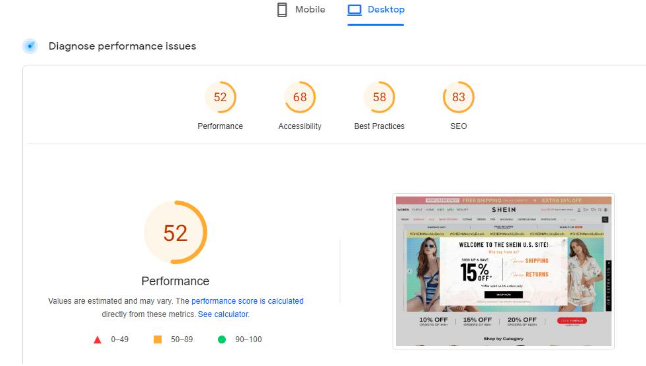
电商网站加速方案:WooCommerce加载从5s到0.9s的实操
APP开发后如何做A/B测试? (转化率提升指南!界面/文案/按钮优化案例)