一、MoE(专家混合模型)基础概念
1. 定义与核心思想
MoE(Mixture of Experts,专家混合模型)是一种先进的机器学习架构,其核心思想是将复杂的任务分解为多个子任务,并由多个“专家”模型分别处理这些子任务,再通过一个“门控网络”(Gating Network)动态地组合各个专家的输出,最终得到整个模型的预测结果。
2. 架构组成
- 专家网络(Experts):多个独立的子模型,每个专家在特定领域或数据分布上具有专长。例如在自然语言处理中,一个专家可能擅长处理语法结构,另一个专家可能擅长处理语义理解。
- 门控网络(Gating Network):负责根据输入数据动态地分配权重给各个专家,决定每个专家对最终输出的贡献程度。门控网络通常使用神经网络实现,通过学习输入数据的特征来生成权重。
3. 分片处理输入的原理
MoE模型通过分片处理输入,将输入数据分配到不同的专家上,每个专家只需要处理自己擅长的数据子集。这种分片处理的方式使得模型能够更加高效地利用计算资源,同时提高模型的泛化能力和准确性。例如,在图像识别任务中,不同专家可以分别处理图像的不同区域或不同特征,从而更全面地捕捉图像的信息。

二、Mixtral模型中的MoE架构解析
1. Mixtral模型简介
Mixtral是一种基于MoE架构的大型语言模型,它通过将MoE思想应用于Transformer架构中,实现了在保持模型性能的同时,显著降低计算成本和参数规模的目标。Mixtral模型在自然语言处理任务中表现出了优异的性能,如文本生成、问答系统、机器翻译等。
2. Mixtral中MoE架构的具体实现
- 专家数量与结构:Mixtral模型中包含多个专家,每个专家都是一个独立的Transformer子网络。这些专家具有相似的结构,但在参数上存在差异,使得它们能够学习到不同的知识表示。例如,Mixtral-8x7B模型包含8个专家,每个专家的参数规模为70亿,整个模型的参数规模约为467亿,但实际推理时每次只激活部分专家,大大降低了计算开销。
- 门控网络设计:Mixtral的门控网络根据输入的文本特征,为每个专家生成一个权重,权重表示该专家对当前输入的贡献程度。门控网络通过学习输入数据的语义信息和上下文关系,动态地调整专家的权重分配,确保最相关的专家能够发挥更大的作用。例如,当输入文本涉及技术领域时,门控网络可能会给擅长技术领域知识处理的专家分配更高的权重。
- 专家协作与输出融合:各个专家根据门控网络分配的权重对输入数据进行处理,生成各自的输出结果。然后,Mixtral模型将这些输出结果进行加权融合,得到最终的预测结果。这种融合方式综合考虑了各个专家的优势,使得模型能够更加准确地理解和生成文本。
3. 分片处理输入在Mixtral中的体现
Mixtral模型在处理输入文本时,会将文本分片成多个部分,并将这些部分分配到不同的专家上。每个专家只对自己负责的文本分片进行处理,生成局部的特征表示。然后,门控网络根据这些局部特征和整体的文本信息,动态地调整专家的权重,实现全局的特征融合和输出生成。例如,在处理一篇长文章时,Mixtral模型可以将文章分成多个段落,每个专家处理一个或多个段落,最后将各个专家的处理结果综合起来,生成对整篇文章的理解和回复。
三、MoE架构(以Mixtral为例)的优势
1. 计算效率提升
由于MoE模型在推理时只激活部分专家,而不是所有专家,因此大大减少了计算量和参数规模。以Mixtral模型为例,相比于同参数规模的密集模型,Mixtral在推理时的计算成本和内存占用都显著降低,能够在相同的硬件资源下处理更多的请求,提高系统的吞吐量。
2. 模型性能优化
通过分片处理输入和专家协作,MoE模型能够更加全面地捕捉输入数据的特征和关系。每个专家在自己擅长的领域进行深度学习,从而提高了模型的整体性能。例如,在自然语言处理任务中,Mixtral模型能够更好地理解文本的语义、语法和上下文信息,生成更加准确和流畅的文本。
3. 可扩展性强
MoE架构具有良好的可扩展性,可以通过增加专家的数量来提升模型的容量和性能。与传统的密集模型相比,增加专家数量不会导致计算成本的线性增长,因为每次推理仍然只激活部分专家。这使得MoE模型能够轻松地扩展到更大的规模,适应不断增长的数据和任务需求。
四、实际案例分析:Mixtral在问答系统中的应用
1. 案例背景
假设我们要构建一个基于Mixtral模型的问答系统,该系统需要能够准确理解用户提出的问题,并从海量的知识库中检索相关信息,生成准确的答案。
2. 系统架构设计
- 输入处理模块:将用户输入的问题进行预处理,如分词、去除停用词等,然后将处理后的问题分片,分配到Mixtral模型的各个专家上。
- Mixtral推理模块:Mixtral模型根据输入的问题分片,由各个专家进行处理,并生成各自的输出结果。门控网络根据问题的特征动态调整专家的权重,将各个专家的输出进行融合,得到对问题的综合理解。
- 知识库检索模块:根据Mixtral模型对问题的理解,从知识库中检索相关的信息。
- 答案生成模块:将检索到的相关信息与Mixtral模型的输出进行整合,生成最终的答案返回给用户。
3. 性能表现与优势体现
- 准确性提升:通过分片处理问题和专家协作,Mixtral模型能够更准确地理解问题的语义和意图,从而从知识库中检索到更相关的信息,生成更准确的答案。例如,对于一些复杂的问题,如涉及多个领域知识的综合性问题,Mixtral模型能够充分发挥各个专家的优势,提供更全面的解答。
- 响应速度加快:由于Mixtral模型在推理时只激活部分专家,计算效率得到显著提升,因此问答系统的响应速度也大大加快。用户能够在更短的时间内得到准确的答案,提高了用户体验。
- 适应性强:Mixtral模型具有良好的可扩展性,当知识库不断更新和扩展时,可以通过增加专家的数量或调整专家的结构来适应新的任务需求,保证问答系统的性能和准确性。
五、MoE架构(以Mixtral为例)的挑战与解决方案
1. 专家负载均衡问题
在MoE模型中,可能会出现部分专家被过度激活,而另一部分专家很少被使用的情况,导致专家负载不均衡。这不仅会影响模型的性能,还会造成计算资源的浪费。
解决方案:
- 引入辅助损失函数:在训练过程中,除了主任务的损失函数外,还可以引入一个辅助损失函数,鼓励门控网络均匀地分配权重给各个专家,使得每个专家都能得到充分的训练。
- 动态调整专家容量:根据专家的负载情况,动态地调整专家的容量,如增加或减少专家的参数规模,以实现负载均衡。
2. 训练难度增加
MoE模型的训练过程相对复杂,因为需要同时训练多个专家和门控网络,并且要考虑专家之间的协作和竞争关系。此外,由于每次推理只激活部分专家,训练数据的采样和优化也变得更加困难。
解决方案:
- 采用分布式训练技术:利用多台机器并行训练MoE模型,提高训练效率。可以将不同的专家分配到不同的机器上进行训练,然后通过参数服务器进行参数的同步和更新。
- 优化训练算法:设计专门针对MoE模型的训练算法,如采用稀疏训练技术,只更新被激活的专家和门控网络的参数,减少计算开销。同时,可以使用更先进的优化器,如AdamW等,来加速模型的收敛。
3. 模型部署与推理优化
虽然MoE模型在推理时能够降低计算成本,但在实际部署过程中,仍然需要考虑如何进一步优化推理性能,以满足实时性要求较高的应用场景。
解决方案:
- 模型压缩与量化:对Mixtral模型进行压缩和量化处理,减少模型的参数规模和计算量。例如,可以采用知识蒸馏技术,将大模型的知识迁移到小模型上,或者使用低精度计算,如FP16或INT8,来加速推理。
- 硬件加速:利用专门的硬件加速器,如GPU、TPU等,来加速MoE模型的推理过程。这些硬件加速器具有强大的并行计算能力,能够显著提高模型的推理速度。
六、未来展望
1. 模型架构的进一步优化
未来,MoE架构有望在专家结构、门控网络设计等方面进行进一步的优化。例如,可以设计更加复杂的专家结构,如引入注意力机制、卷积神经网络等,以提高专家的表达能力。同时,可以探索更加智能的门控网络设计,使得门控网络能够更好地理解输入数据的特征和任务需求,实现更精准的专家权重分配。
2. 与其他技术的融合
MoE架构可以与其他先进的机器学习技术进行融合,如强化学习、迁移学习等。通过与强化学习的融合,MoE模型可以根据环境的反馈动态地调整专家的权重和结构,实现自适应的学习和优化。通过与迁移学习的融合,MoE模型可以利用预训练的知识来加速新任务的学习,提高模型的泛化能力。
3. 在更多领域的应用拓展
随着MoE架构的不断发展和完善,它有望在更多的领域得到应用,如计算机视觉、语音识别、多模态学习等。在计算机视觉领域,MoE模型可以用于图像分类、目标检测等任务,通过分片处理图像的不同区域,提高模型的准确性和鲁棒性。在语音识别领域,MoE模型可以用于处理不同口音、语速的语音信号,提高语音识别的性能。在多模态学习领域,MoE模型可以整合不同模态的信息,如文本、图像、音频等,实现更加智能的应用。
扫描下方二维码,一个老毕登免费为你解答更多软件开发疑问!

物业管理工单AI调度方案:维修响应缩短至30分钟的核心算法
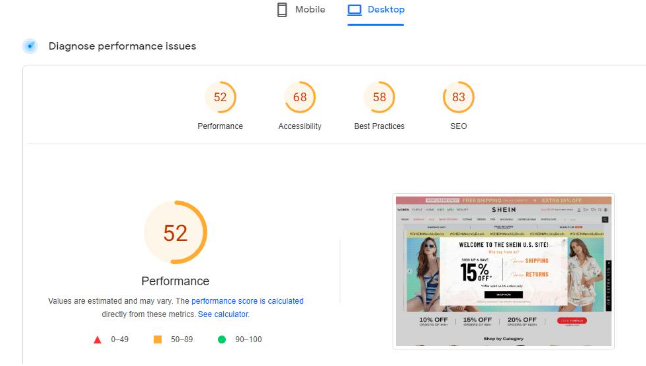
电商网站加速方案:WooCommerce加载从5s到0.9s的实操
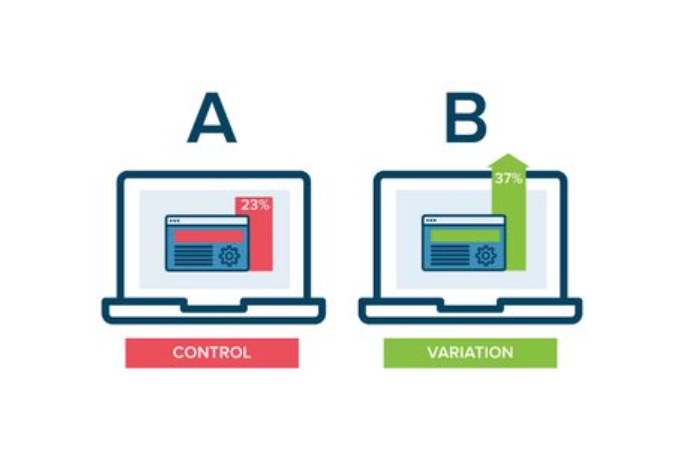
APP开发后如何做A/B测试? (转化率提升指南!界面/文案/按钮优化案例)