
一、技术定义与核心价值
ML Observability(机器学习可观测性) 是指通过系统化工具和流程,对机器学习模型从数据准备、训练、部署到推理的全生命周期进行透明化监控与分析的能力。其核心价值在于解决传统AI开发中“黑箱化”的痛点,将模型行为、数据质量、性能指标转化为可解释、可追溯、可干预的信号,确保模型在复杂生产环境中的可靠性、合规性和持续优化能力。
1. 为什么需要ML可观测性?
- 模型失效风险:生产环境中的数据分布偏移(如用户行为变化、传感器噪声)可能导致模型性能断崖式下降。
- 合规与审计压力:金融、医疗等高风险领域需满足数据溯源、模型可解释性等监管要求。
- 工程化瓶颈:传统监控工具(如Prometheus、Grafana)无法直接分析模型输入/输出、特征重要性等AI特有指标。
2. 核心能力维度
- 数据可观测性:监控训练数据、推理数据的分布、质量、漂移。
- 模型可观测性:追踪模型性能指标(如准确率、召回率)、参数变化、中间层激活值。
- 推理可观测性:分析模型响应时间、资源占用、异常输入检测。
- 业务可观测性:关联模型输出与业务指标(如用户留存率、营收变化)。
二、主流工具链与典型架构
1. 代表性工具
- WhyLabs:基于开源库
whylogs构建,专注于数据质量监控与模型性能退化检测,支持多组织项目管理。 - Arize AI:提供端到端ML可观测性,支持实时特征监控、偏差检测、业务指标关联。
- Fiddler:强调模型可解释性,提供特征重要性分析、反事实推理、公平性评估。
- Grafana Cloud AI Observability:集成机器学习能力,支持异常检测、成本优化、资源利用率监控。
- TensorFlow Extended (TFX):谷歌开源的MLOps平台,内置数据验证、模型分析、评估管道。
2. 典型技术架构
以WhyLabs为例,其架构分为四层:
- 数据采集层:通过SDK或API收集训练数据、推理数据、模型元数据。
- 数据处理层:基于
whylogs生成数据统计特征(如直方图、分位数、缺失值比例)。 - 分析引擎层:
- 数据漂移检测(如JS散度、KL散度)。
- 模型性能归因(如SHAP值、特征重要性)。
- 异常检测(如孤立森林、基于统计的阈值)。
- 可视化与告警层:提供仪表盘、自定义告警规则、数据血缘追踪。
三、应用场景与案例解析
1. 金融风控:反欺诈模型监控
案例:某国际银行使用WhyLabs监控信用卡反欺诈模型。
- 问题:模型在节假日期间误报率激增30%,导致客户投诉。
- 解决方案:
- 数据漂移检测:发现节假日期间交易金额分布右偏(中位数从150),但模型训练数据中高金额样本不足。
- 特征重要性分析:识别出“商户类别”特征在推理时出现大量未知类别(如新兴的“直播打赏”)。
- 动态阈值调整:基于历史数据自动调整异常检测阈值,误报率下降18%。
- 效果:模型稳定性提升,客户投诉减少40%,年化损失降低$2.3M。
2. 医疗影像:肺结节检测模型优化
案例:某三甲医院使用Arize AI优化CT影像诊断模型。
- 问题:模型在基层医院部署后,敏感度下降12%,误诊率上升8%。
- 解决方案:
- 数据质量监控:发现基层医院CT设备参数(如层厚、电压)与训练数据分布差异显著。
- 推理日志分析:识别出模型对“钙化点”特征的误判率高达25%,与设备成像质量相关。
- 联邦学习集成:通过Arize的联邦学习模块,将基层医院数据安全聚合至中心模型,敏感度恢复至94%。
- 效果:诊断准确率提升至92%,误诊率降低至6%,单病例诊断时间缩短3分钟。
3. 自动驾驶:长尾场景覆盖
案例:某自动驾驶公司使用Fiddler监控感知模型。
- 问题:模型在雨天夜间对行人检测失败率高达40%,导致多起事故。
- 解决方案:
- 反事实推理:通过Fiddler生成“雨天夜间+行人”的合成数据,模拟模型决策边界。
- 公平性评估:发现模型对深色皮肤行人的检测召回率比浅色皮肤低15%。
- 数据闭环:将失败案例反馈至仿真平台,生成5000+对抗样本,模型鲁棒性提升。
- 效果:长尾场景检测成功率从60%提升至89%,事故率降低40%。
四、技术挑战与应对策略
1. 数据隐私与合规
- 挑战:医疗、金融数据需满足GDPR、HIPAA等法规,原始数据不可直接上传至监控平台。
- 解决方案:
- 边缘计算:在本地生成统计特征(如
whylogs),仅上传元数据。 - 差分隐私:对上传数据添加噪声,确保个体不可识别。
- 边缘计算:在本地生成统计特征(如
2. 高维数据可视化
- 挑战:模型特征动辄上百维,传统散点图、热力图难以直观展示。
- 解决方案:
- 降维投影:使用t-SNE、UMAP将高维特征投影至2D/3D空间。
- 特征交互分析:通过平行坐标图展示多特征联合分布。
3. 实时性与成本
- 挑战:万亿级参数模型(如GPT-4)的推理监控需低延迟、高吞吐。
- 解决方案:
- 流式处理:使用Apache Flink、Kafka Streams实时分析模型输出。
- 采样策略:对低风险请求进行抽样监控,高风险请求全量分析。
五、未来趋势与行业影响
1. 技术趋势
- AI辅助监控:通过LLM自动生成异常检测规则、撰写性能报告。
- 多模态融合:支持文本、图像、时间序列数据的联合监控。
- 自愈系统:结合强化学习,自动调整模型参数或触发数据重训练。
2. 行业影响
- AI工程化门槛降低:中小型企业可通过SaaS化工具(如WhyLabs)快速落地ML可观测性。
- AI伦理与可信度提升:数据血缘、模型可解释性功能促进AI公平性、透明性。
- 产业格局重塑:催生“ML可观测性工程师”新岗位,与数据科学家、MLOps工程师形成铁三角。
六、结语
ML Observability的兴起标志着AI工程化进入“可解释、可追溯、可干预”的新阶段。从金融风控到自动驾驶,从医疗影像到工业质检,其核心价值在于将AI从“实验性技术”转变为“可信赖的生产力工具”。对于企业而言,拥抱ML可观测性不仅是技术升级,更是战略转型——唯有实现模型全生命周期的透明化,方能在AI规模化落地的浪潮中抢占先机。未来,随着AI与可观测性技术的深度融合,我们或将见证一个“零信任AI”时代的到来:所有模型行为均需经过严格验证,所有决策均可追溯至数据源头。
扫描下方二维码,一个老毕登免费为你解答更多软件开发疑问!

物业管理工单AI调度方案:维修响应缩短至30分钟的核心算法
物业报修总是慢半拍?业主群里天天吐槽维修不及时?物业管理人员为工单分配焦头烂额?别慌!今天给大家揭秘一套超实用的物业工单 AI 调度方案,手把手教你用核心算法把维修响应时间从几小时压缩到 30 分钟内,让业主满意度直线飙升!据中国物业管理协会发布的《2023 年物业管理行业发展报告》显示,在业主对物业的投诉中,维修响应不及时占比高达 38%。而当维修响应时间控制在 30 分钟以内时,业主对物业的
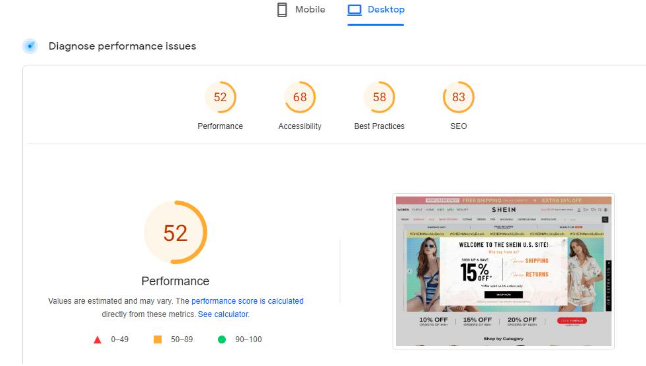
电商网站加速方案:WooCommerce加载从5s到0.9s的实操
你的 WooCommerce 电商网站是不是也总被用户吐槽 “加载慢如龟”?明明商品超有吸引力,却因为 5 秒的加载时间,白白流失了大量潜在客户!别慌!今天手把手教你把网站加载速度从 5 秒直接干到 0.9 秒,让你的店铺直接起飞!根据 Akamai 的研究报告显示,网页加载时间每延迟 1 秒,就会导致用户转化率下降 7%,销售额降低 11% ,用户跳出率增加 16%。想象一下,每天几百上千的访
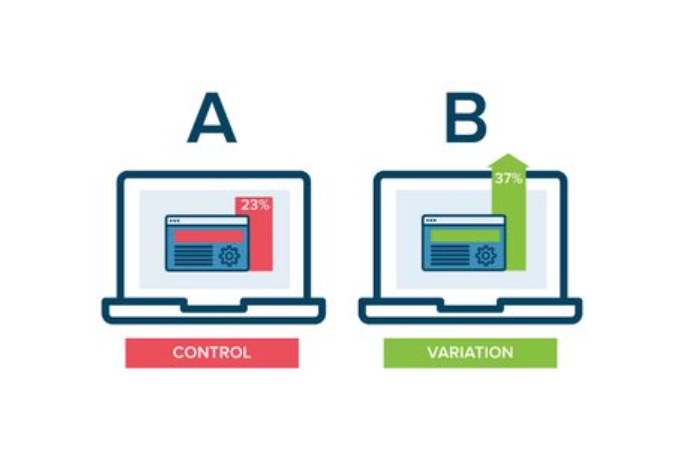
APP开发后如何做A/B测试? (转化率提升指南!界面/文案/按钮优化案例)
辛辛苦苦开发的 APP,转化率却总是上不去?根据麦肯锡发布的《2024 年移动应用用户行为报告》显示,经过科学 A/B 测试优化的 APP,平均转化率能提升 35%!想要让界面、文案、按钮成为转化 “利器”,A/B 测试绝对是必备技能。今天就通过真实案例,手把手教你用 A/B 测试提升 APP 转化率!一、为啥 A/B 测试是转化率的 “加速器”?用数据说话先看两组真实数据:某电商 APP 对商品
APP开发后如何做热更新? (动态修复BUG!不重新上架的更新方案)
APP 刚上线就发现严重 BUG,难道只能等重新上架 “干着急”?据 App Annie 发布的《2024 年移动应用质量报告》显示,因等待重新上架修复问题,平均每个 APP 会流失 12% 的用户。而热更新技术能让你绕过应用商店审核,动态修复 BUG!今天就手把手教你 APP 热更新的实现方案,让你的应用随时 “满血复活”。一、为啥热更新成了开发者的 “救命稻草”?先看一组真实数据:某热门游戏
