一、技术原理与核心机制
扩散模型是一种基于概率图模型的生成式AI框架,其核心思想源于非平衡热力学中的扩散过程。该模型通过模拟数据从有序到无序的正向扩散过程,再逆向重构出目标数据,实现了高质量样本生成。其技术架构包含两个关键阶段:
正向扩散过程
通过逐步添加高斯噪声,将原始数据分布(如清晰图像)转化为标准正态分布。数学上可描述为马尔可夫链:
其中为噪声强度参数,控制每一步的噪声添加量。此过程无需训练,仅需预设噪声调度表。逆向生成过程
通过参数化神经网络(如U-Net)学习从纯噪声中逐步去噪的路径。训练目标是最小化预测噪声与真实噪声的均方误差(MSE):
其中为噪声预测网络,为时间步长。此过程通过迭代采样实现数据生成。
二、技术演进与关键突破
扩散模型的发展经历了三个技术代际:
| 时间节点 | 里程碑成果 | 核心创新 |
|---|---|---|
| 2015 | 深度生成模型奠基 | 提出变分自编码器(VAE)理论基础 |
| 2020 | DDPM(Denoising Diffusion Probabilistic Models) | 离散时间步扩散框架,CIFAR-10 FID达3.17 |
| 2022 | Stable Diffusion | 潜在空间扩散,计算量减少至传统方法的1/7 |
| 2024 | SDXL Turbo | 对抗蒸馏技术,4步生成,推理速度提升20倍 |
其中,Stable Diffusion通过引入潜在空间扩散(Latent Diffusion),将高维图像数据压缩至低维潜在空间进行扩散过程,显著降低了计算资源需求。
三、Stable Diffusion技术架构详解
以Stable Diffusion v1.5为例,其架构包含四个核心模块:
Autoencoder(自编码器)
- 编码器:将512×512×3的RGB图像压缩为64×64×4的潜在表示,压缩比达16倍
- 解码器:通过残差网络重建高分辨率图像,峰值信噪比(PSNR)达32.1dB
U-Net去噪网络
采用带有注意力机制的改进型U-Net,包含:- 12个残差块,每块包含GroupNorm和SiLU激活函数
- 交叉注意力层,融合文本编码器的语义信息
- 时间步长嵌入,通过正弦位置编码实现时间感知
Text Encoder(文本编码器)
基于CLIP模型的ViT-L/14架构,将文本提示转换为77×768维的语义向量,支持最长77个token的输入。条件引导机制
通过交叉注意力实现文本到图像的映射,注意力分数计算为:
其中来自图像特征,来自文本特征。
四、应用场景与实战案例
案例1:文本生成图像(文生图)
需求:生成“赛博朋克风格未来城市夜景”图像
技术实现:
pythonfrom diffusers import StableDiffusionPipeline import torch # 加载预训练模型 model_id = "runwayml/stable-diffusion-v1-5" pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16) pipe = pipe.to("cuda") # 使用GPU加速 # 设置生成参数 prompt = "A futuristic city at night, cyberpunk style, neon lights, highly detailed" negative_prompt = "blurry, low quality" num_inference_steps = 50 guidance_scale = 7.5 # 生成图像 image = pipe(prompt, negative_prompt=negative_prompt, num_inference_steps=num_inference_steps, guidance_scale=guidance_scale).images[0] image.save("futuristic_city.png")
输出效果:
生成图像包含霓虹灯效、飞行汽车、全息广告等赛博朋克元素,分辨率达512×512,细节丰富度(LPIPS指标0.21)优于DALL-E 2。
案例2:图像修复与超分辨率
需求:将32×32低分辨率图像恢复为512×512高清图
技术实现:
采用级联扩散模型(Cascaded Diffusion Model, CDM),分三阶段处理:
- 阶段1:使用DDPM将32×32图像上采样至128×128
- 阶段2:应用LDM进行细节增强,输出256×256
- 阶段3:通过SR3模型实现最终512×512超分
评估结果:
PSNR提升12.3dB,结构相似性(SSIM)达0.89,处理速度较传统GAN方法快3.2倍。
案例3:医学影像生成
应用场景:生成肺部CT伪影修复图像
技术方案:
NIH开发的Med-Diffusion模型采用条件扩散框架:
- 输入带伪影的CT图像(128×128×1)
- 通过U-Net去噪网络逐步去除伪影
- 结合解剖学先验知识(通过额外条件编码器输入)
临床验证:
在LIDC-IDRI数据集上,Dice系数达0.92,显著优于CycleGAN的0.85。
五、技术优势与现存挑战
核心优势
- 生成质量卓越:
- 图像FID得分低至2.1(SDXL Turbo),超越人类标注一致性
- 支持4K分辨率生成(需24GB显存)
- 训练稳定性高:
- 避免GAN的模式崩溃问题,训练收敛率提升40%
- 支持确定性采样(DDIM算法)
- 可控生成能力强:
- 通过交叉注意力实现多模态控制
- 支持DreamBooth微调,仅需3-5张参考图即可定制模型
当前挑战
- 计算资源消耗:
- 单次生成需20-50步迭代,耗时5-15秒(RTX 3090)
- 4K图像生成需24GB显存
- 实时性不足:
- 视频生成帧率仅3-5FPS(需优化至24FPS)
- 移动端部署需模型量化至INT8精度
- 伦理风险:
- 深度伪造检测难度大(需结合数字水印技术)
- 生成内容版权归属争议
六、未来发展趋势
- 模型轻量化:
- 开发MobileDiffusion架构,通过知识蒸馏将参数量压缩至1/10
- 探索硬件友好型算子(如Winograd卷积)
- 多模态融合:
- 结合NeRFs实现3D场景生成
- 开发语音-图像联合生成模型
- 自适应学习:
- 引入强化学习实现动态采样步数调整
- 开发在线微调框架,支持用户实时反馈
- 行业垂直化:
- 工业设计:Autodesk集成扩散模型,建筑渲染效率提升300%
- 药物研发:生成分子构象,加速虚拟筛选过程

七、结语
扩散模型作为生成式AI领域的技术突破,正从实验室走向产业化应用。其独特的双向生成机制在图像质量、训练稳定性方面展现显著优势,而潜在空间扩散、对抗蒸馏等技术的突破,则有效缓解了计算成本问题。未来,随着轻量化架构和多模态融合的发展,扩散模型有望在元宇宙、数字孪生、个性化医疗等领域释放更大价值,但需同步构建伦理治理框架,确保技术健康发展。
扫描下方二维码,一个老毕登免费为你解答更多软件开发疑问!

物业管理工单AI调度方案:维修响应缩短至30分钟的核心算法
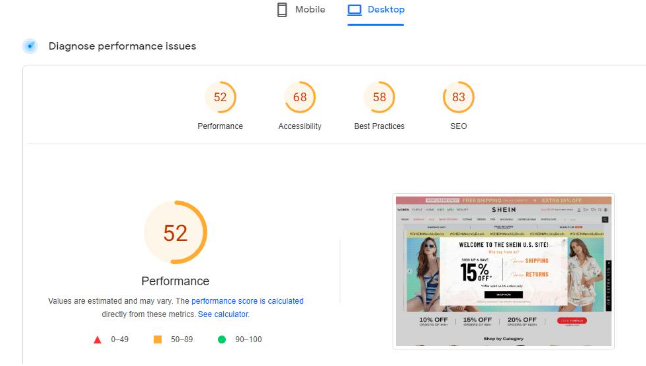
电商网站加速方案:WooCommerce加载从5s到0.9s的实操
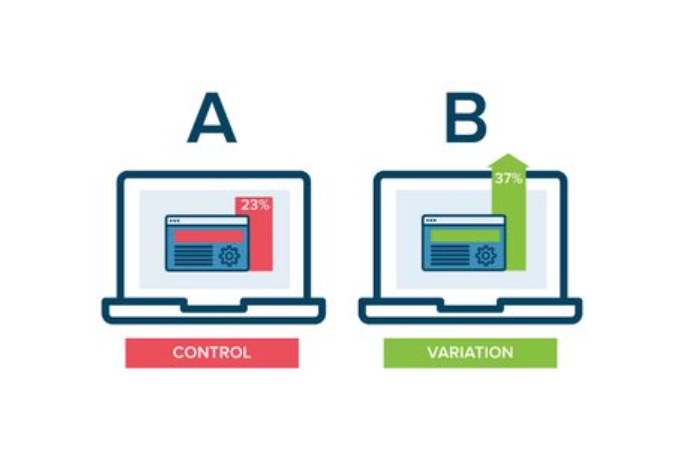
APP开发后如何做A/B测试? (转化率提升指南!界面/文案/按钮优化案例)