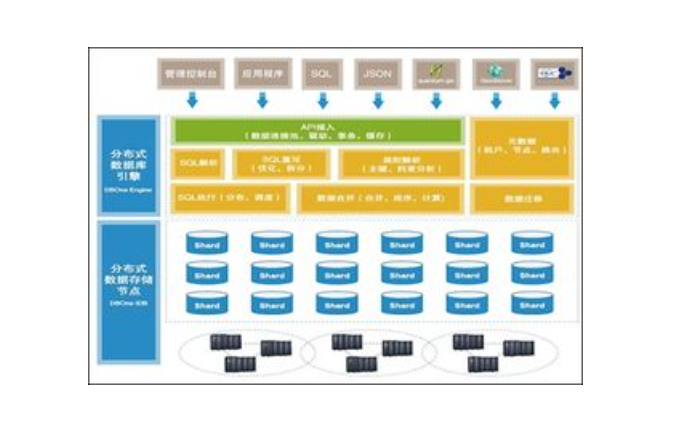
分布式数据库是数据库技术的一个重要发展方向,它通过将数据分散存储在多个物理节点上,并利用网络通信实现数据的共享和透明访问,从而解决了单机数据库的扩展性问题,提高了系统的可用性、可靠性和性能。以下是对分布式数据库的详细解释,包括其定义、原理、特点、关键技术、应用场景以及一个实例形象的讲解。
一、定义与原理
分布式数据库是由一组数据组成,这组数据分布在计算机网络的不同计算机上,网络中的每个节点具有独立处理的能力(或称为场地自治能力),可以执行局部应用,同时每个节点也能通过网络通信子系统执行全局应用。简单来说,分布式数据库是利用高速网络(如互联网)将分散的多个局域网中的数据存储单元连接起来组成一个逻辑上集中的全局数据库,可以获取更大的存储容量和更高的并发访问量。
分布式数据库的原理在于将数据分散到多个节点,以提高系统的可用性、可扩展性和容错性。在分布式数据库中,数据被分割成多个部分,并存储在不同的节点上。这些节点通过网络相互连接,可以共同处理查询、更新等数据库操作。分布式数据库管理系统(DDBMS)负责协调这些节点之间的通信和数据交换,以确保数据的一致性和完整性。
二、特点
- 数据分布性:数据分布在多个计算机上,可以分散存储压力,避免单点故障。
- 数据并行处理:多个计算机可以同时处理数据,显著提高数据处理速度。
- 数据一致性:通过分布式事务处理等技术确保数据的一致性。虽然分布式系统中可能存在数据不一致的情况,但通过合适的机制和算法,可以使得数据在最终状态下达到一致。
- 数据可扩展性:可以方便地增加更多的计算机来扩展系统的处理能力,满足不断增长的数据量和处理需求。
- 高可用性和可扩展性:分布式数据库能够灵活扩展并确保不间断服务。
- 管理不同透明度的数据:分布式数据库系统可以管理不同透明度的数据,使得数据的管理更加灵活和方便。
三、关键技术
- 数据分片:将数据分割成多个部分并存储在不同的节点上。数据分片可以提高系统的可扩展性和并行处理能力。
- 数据复制:在每个节点上存储数据的副本,以提高系统的容错性和可用性。当某个节点发生故障时,可以从其他节点上获取数据的副本来恢复数据。
- 分布式事务处理:在多个节点上执行一系列操作,这些操作要么全部成功,要么全部失败。分布式事务处理需要协调各个节点之间的操作,以确保数据的一致性和完整性。
- 数据一致性保障:通过合适的机制和算法来保障数据的一致性。例如,可以使用两阶段提交协议(2PC)或三阶段提交协议(3PC)等算法来协调各个节点之间的操作,以确保数据在最终状态下达到一致。
四、应用场景
分布式数据库的应用场景非常广泛,涵盖了多个行业和领域,包括但不限于:
- 互联网和电子商务平台:分布式数据库能够处理大量用户生成的数据和实时互动,例如社交媒体、在线购物和金融交易平台。
- 金融服务:分布式数据库可以支持银行的分行、支行等分支机构的业务处理,确保跨地区的交易数据的一致性和完整性。
- 物联网(IoT):物联网涉及大量的传感器数据和设备数据,这些数据需要进行实时处理和分析。分布式数据库可以将数据存储在离数据源最近的节点上,减少数据传输的延迟,提高数据的实时性。
- 大数据分析:分布式数据库在数据湖中能够存储和处理海量数据,结合Hadoop与Spark进行大数据分析。
- 云计算平台:随着云计算技术的发展,分布式数据库在云服务中扮演着重要角色。它们提供了数据存储、管理和分析的服务,支持多种数据模型和查询语言,使得用户可以在云环境中灵活地处理数据。
五、实例讲解
以某大型电商公司为例,该公司采用传统的集中式数据库来存储和管理用户订单、购物车等核心业务数据。然而,随着业务规模的不断扩大,集中式数据库逐渐无法满足性能和可靠性的需求。具体表现为订单处理速度缓慢、购物车数据丢失等问题,严重影响了用户体验和业务效益。
为了解决这些问题,该电商公司决定采用分布式数据库技术进行升级改造。通过将数据分散存储在多个节点上,实现了高性能和可靠性提升。同时,采用多副本技术确保数据的可靠存储,即使部分节点发生故障,系统也能自动切换到备份节点,保证业务持续可用。此外,通过分布式事务处理机制确保跨节点操作的数据一致性,有效避免了传统集中式数据库中可能出现的数据不一致问题。
经过分布式数据库升级改造后,该电商公司的业务性能和可靠性得到了显著提升。用户可以更加顺畅地进行购物操作,提升了用户体验。同时,系统能够轻松应对业务数据的快速增长,为公司的未来发展提供了有力保障。
综上所述,分布式数据库作为数据库技术的一个重要发展方向,具有显著的优势和广泛的应用场景。随着技术的不断进步和市场的不断发展,分布式数据库将越来越成熟和完善,为各种应用场景提供更加高效、可靠和智能的数据管理服务。
扫描下方二维码,一个老毕登免费为你解答更多软件开发疑问!

物业管理工单AI调度方案:维修响应缩短至30分钟的核心算法
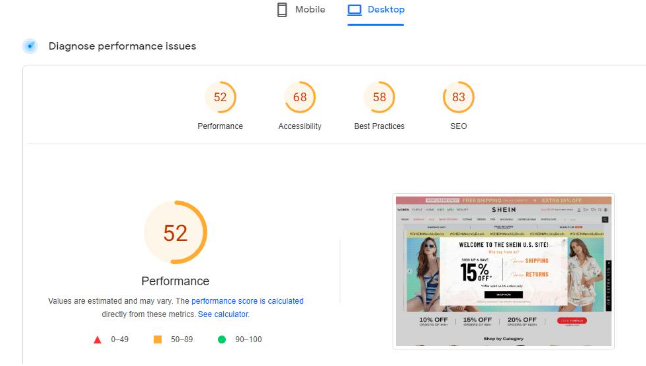
电商网站加速方案:WooCommerce加载从5s到0.9s的实操
APP开发后如何做A/B测试? (转化率提升指南!界面/文案/按钮优化案例)