数据预处理是数据分析、数据挖掘以及机器学习等领域中的一个关键步骤,它指的是在将数据输入到模型或算法之前,对数据进行的一系列必要处理操作。这些操作旨在提高数据的质量、一致性和适用性,从而确保后续分析和建模的准确性和有效性。以下是对数据预处理的详细解释,包括其定义、目的、常见方法以及一个实例形象的讲解。
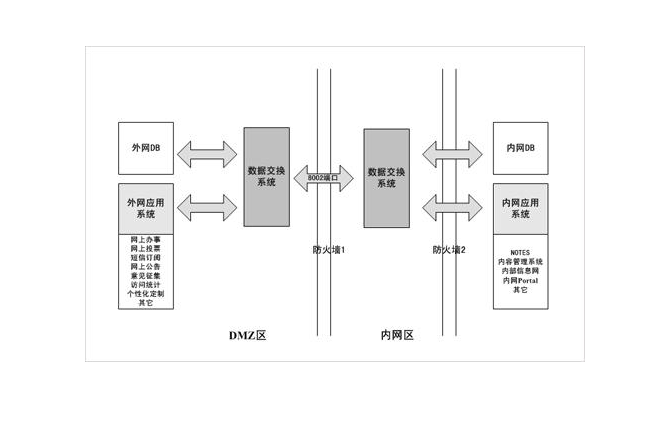
一、数据预处理的定义与目的
数据预处理是指在数据分析或数据挖掘之前,对原始数据进行清洗、筛选、转换、特征选择和提取等一系列处理操作的过程。其目的主要包括以下几个方面:
- 提高数据质量:原始数据中可能包含缺失值、异常值、重复值等问题,数据预处理可以消除这些问题,提高数据的准确性和完整性。
- 增强数据一致性:不同来源的数据可能具有不同的格式和单位,数据预处理可以统一这些格式和单位,使数据更加一致和可比。
- 降低模型复杂度:通过数据预处理,可以提取出对后续分析有用的特征,同时去除无关或冗余的特征,从而降低模型的复杂度。
- 提高模型性能:高质量的数据可以显著提高模型的准确性和泛化能力,数据预处理是确保数据质量的重要手段。
二、数据预处理的常见方法
- 数据清洗:包括处理缺失值(如填充、删除或插值)、处理异常值(如删除、替换或修正)以及去除重复值等。
- 数据转换:包括数据类型转换(如将字符串转换为数值类型)、数据标准化或归一化(如将数据缩放到特定范围)、数据离散化(如将连续变量转换为离散变量)等。
- 特征选择:从原始特征中选择出对后续分析有用的特征,去除无关或冗余的特征。特征选择可以基于统计方法、机器学习算法或领域知识等。
- 特征提取:通过某种方法(如主成分分析、线性判别分析等)从原始特征中提取出新的特征,这些新特征可能更能反映数据的本质特性。
- 数据降噪:通过滤波、平滑等方法去除数据中的噪声,提高数据的信噪比。
- 数据增强:在机器学习领域,特别是深度学习领域,数据增强是一种通过变换原始数据(如旋转、缩放、翻转等)来生成更多训练样本的方法,以提高模型的泛化能力。
三、实例讲解:使用Pandas进行数据预处理
以下是一个使用Pandas库进行数据预处理的实例,该实例包括读取数据、处理缺失值、处理异常值、数据类型转换以及特征选择等步骤。
pythonimport pandas as pd import numpy as np # 读取数据 data = pd.read_csv('data.csv') # 查看数据前五行 print(data.head()) # 处理缺失值:填充缺失值(以平均值填充为例) data['column_with_missing_values'].fillna(data['column_with_missing_values'].mean(), inplace=True) # 处理异常值:删除异常值(以删除房价小于0的记录为例) data = data[data['house_price'] >= 0] # 数据类型转换:将字符串类型的房价转换为数值类型 data['house_price'] = pd.to_numeric(data['house_price'], errors='coerce') # 去除转换失败(即无法转换为数值类型)的记录 data = data.dropna(subset=['house_price']) # 特征选择:选择有用的特征(以选择面积和房价为例) selected_features = data[['area', 'house_price']] # 查看处理后的数据 print(selected_features.head())
在这个实例中,我们首先使用Pandas读取了一个CSV文件中的数据。然后,我们处理了缺失值,通过填充平均值来填补缺失值。接着,我们处理了异常值,删除了房价小于0的记录。之后,我们进行了数据类型转换,将字符串类型的房价转换为数值类型,并去除了转换失败的记录。最后,我们选择了有用的特征,即面积和房价,作为后续分析的基础。
通过这个实例,我们可以看到数据预处理在数据分析中的重要性。通过一系列的处理操作,我们可以提高数据的质量、一致性和适用性,从而为后续的分析和建模提供可靠的基础。
扫描下方二维码,一个老毕登免费为你解答更多软件开发疑问!

物业管理工单AI调度方案:维修响应缩短至30分钟的核心算法
物业报修总是慢半拍?业主群里天天吐槽维修不及时?物业管理人员为工单分配焦头烂额?别慌!今天给大家揭秘一套超实用的物业工单 AI 调度方案,手把手教你用核心算法把维修响应时间从几小时压缩到 30 分钟内,让业主满意度直线飙升!据中国物业管理协会发布的《2023 年物业管理行业发展报告》显示,在业主对物业的投诉中,维修响应不及时占比高达 38%。而当维修响应时间控制在 30 分钟以内时,业主对物业的
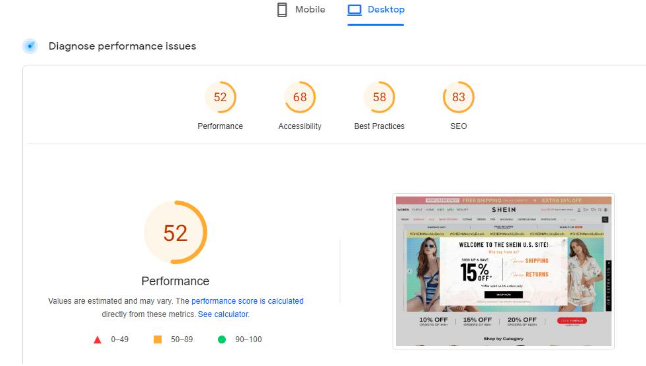
电商网站加速方案:WooCommerce加载从5s到0.9s的实操
你的 WooCommerce 电商网站是不是也总被用户吐槽 “加载慢如龟”?明明商品超有吸引力,却因为 5 秒的加载时间,白白流失了大量潜在客户!别慌!今天手把手教你把网站加载速度从 5 秒直接干到 0.9 秒,让你的店铺直接起飞!根据 Akamai 的研究报告显示,网页加载时间每延迟 1 秒,就会导致用户转化率下降 7%,销售额降低 11% ,用户跳出率增加 16%。想象一下,每天几百上千的访
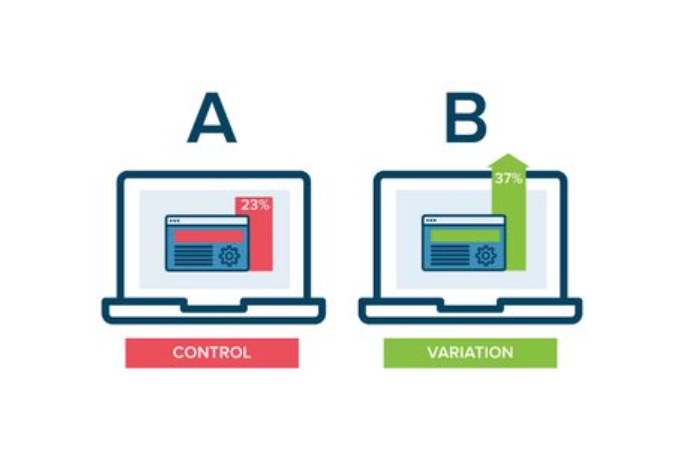
APP开发后如何做A/B测试? (转化率提升指南!界面/文案/按钮优化案例)
辛辛苦苦开发的 APP,转化率却总是上不去?根据麦肯锡发布的《2024 年移动应用用户行为报告》显示,经过科学 A/B 测试优化的 APP,平均转化率能提升 35%!想要让界面、文案、按钮成为转化 “利器”,A/B 测试绝对是必备技能。今天就通过真实案例,手把手教你用 A/B 测试提升 APP 转化率!一、为啥 A/B 测试是转化率的 “加速器”?用数据说话先看两组真实数据:某电商 APP 对商品
APP开发后如何做热更新? (动态修复BUG!不重新上架的更新方案)
APP 刚上线就发现严重 BUG,难道只能等重新上架 “干着急”?据 App Annie 发布的《2024 年移动应用质量报告》显示,因等待重新上架修复问题,平均每个 APP 会流失 12% 的用户。而热更新技术能让你绕过应用商店审核,动态修复 BUG!今天就手把手教你 APP 热更新的实现方案,让你的应用随时 “满血复活”。一、为啥热更新成了开发者的 “救命稻草”?先看一组真实数据:某热门游戏
